Continue with last article, only paste code here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
int ping(/*in*/ const char *ip, /*out*/ int *ttl, /*out*/ int *diff) { HANDLE hIcmpFile; LPVOID lpReplyBuffer; DWORD dwReplySize, dwRetVal, dwTick; int ret; static const char szSendData[] = "IcmpSendEcho ping"; ret = -1; hIcmpFile = NULL; do { dwTick = GetTickCount(); /* send ping */ hIcmpFile = IcmpCreateFile(); if (hIcmpFile == INVALID_HANDLE_VALUE) { break; } dwReplySize = sizeof(ICMP_ECHO_REPLY) + sizeof(szSendData); lpReplyBuffer = (void *)malloc(dwReplySize); dwRetVal = IcmpSendEcho(hIcmpFile, inet_addr(ip), (LPVOID)szSendData, sizeof(szSendData), NULL, lpReplyBuffer, dwReplySize, 5000); if (dwRetVal != 0) { /* use the first reply */ PICMP_ECHO_REPLY pReply; pReply = (PICMP_ECHO_REPLY)lpReplyBuffer; *ttl = pReply->Options.Ttl; *diff = GetTickCount() - dwTick; ret = 0; } } while (0); if (hIcmpFile) { IcmpCloseHandle(hIcmpFile); } return ret; } |
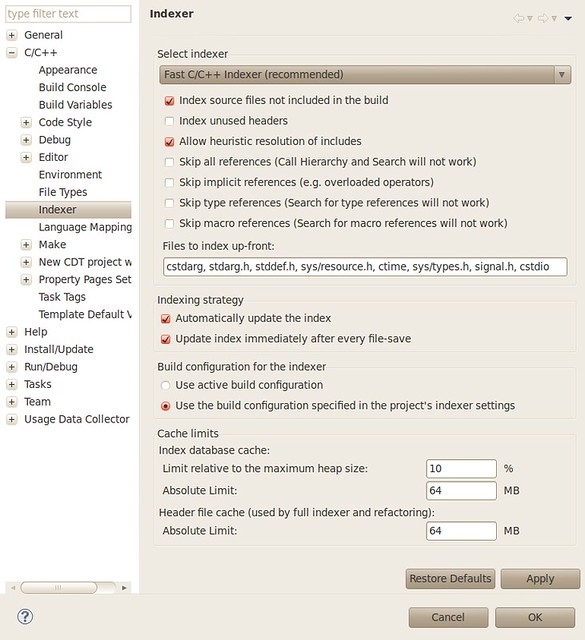
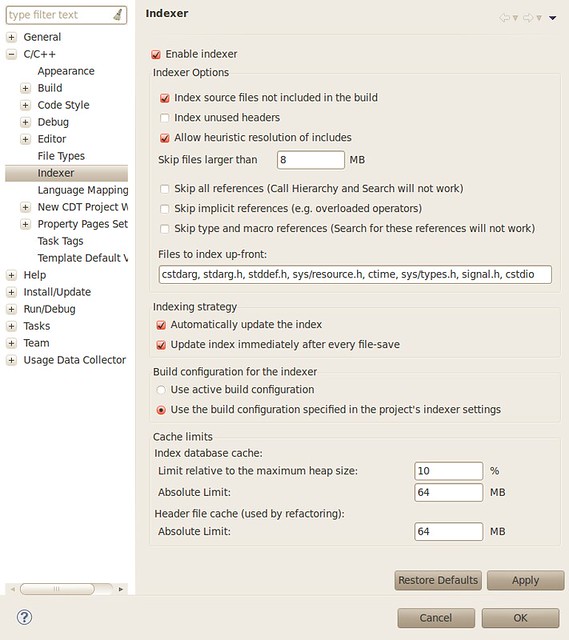
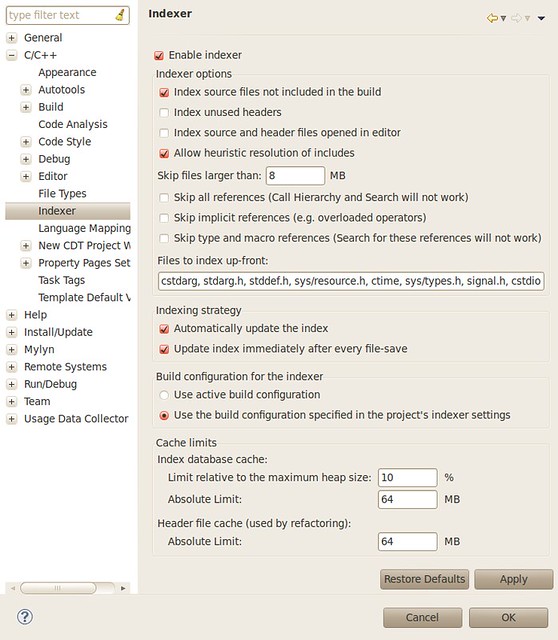
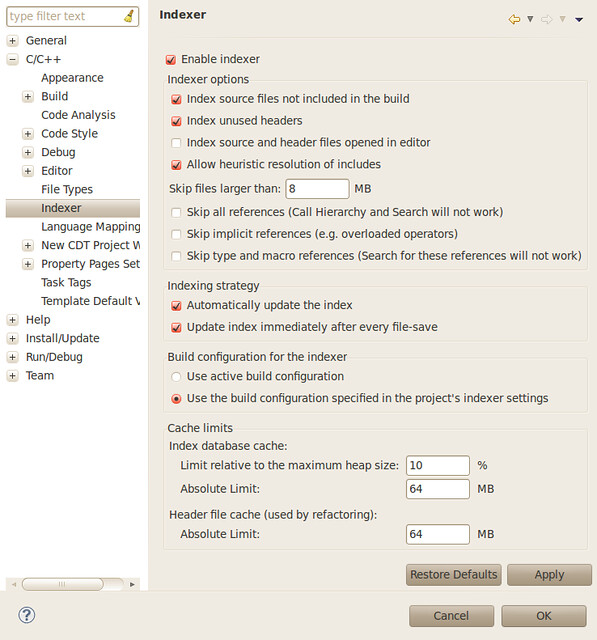
IcmpSendEcho() is used to send ICMP messages which does not require administrator privilege. I summarize all cases in which raw socket, icmp api or system ping approach may fail:
| raw socket | icmp api | system ping | ||
| Windows XP | Administrator | OK | OK | OK |
| User | WSAEACCES in sendto() | OK | OK | |
| Guest | WSAEACCES in sendto() | OK | OK | |
| Windows 7 | Administrator | WSAEACCES in socket() | OK | OK |
| User | WSAEACCES in socket() | OK | OK | |
| Guest | WSAEACCES in socket() | ERROR_ACCESS_DENIED in IcmpCreateFile() | Unable to contact IP driver. General failure. | |
| Run as Administrator | OK | OK | OK | |
You may ask what’s the difference between “Administrator” and “Run as Administrator”, the answer comes from stackoverflow:
– When an user from the administrator group logs on, the user is allocated two tokens: a token with all privileges, and a token with reduced privileges. When that user creates a new process, the process is by default handed the reduced privilege token. So, although the user has administrator rights, she does not exercise them by default. This is a “Good Thing”.
– To exercise those rights the user must start the process with elevated rights. For example, by using the “Run as administrator” verb. When she does this, the full token is handed to the new process and the full range of rights can be exercised.